
Predictive coding software analyzes documents that a human reviewer has tagged as relevant or not relevant to learn to identify relevant documents. The software may produce a binary yes/no relevance prediction for each unreviewed document, or it may produce a relevance score. This article aims to clear up some confusion about what the relevance score measures, which should make its importance clear.
Ralph Losey’s recent article “Relevancy Ranking is the Key Feature of Predictive Coding Software” generated some debate and controversy reflected in the readers’ comments. To appreciate the value in producing a relevance score or ranking, rather than just a yes/no relevance prediction for each document, it is critical to understand what the relevance score really measures.
Predictive coding software that produces a relevance score allows documents to be ordered, or ranked, while software that produces a yes/no relevance prediction only allows documents to be separated into two unordered sets. What does the ordering generated by the relevance score mean? What causes a document to float to the top when predictive coding is applied? The documents at the top are not the most relevant documents, contrary to misconceptions encouraged by sloppy language on the subject. Rather, they are the documents that the algorithm thinks are most likely to be relevant. If there is a “hot document” or a “smoking gun” in the document set, there is no reason to believe that it will be the first, or even the second document in the ordered list. The algorithm will put the document it is most confident is relevant at the top of the list.
What gives an algorithm confidence that a document is relevant, causing it to move to the top of the list? That depends on the algorithm. An algorithm may have high confidence if the document is highly similar to one of the human-reviewed documents from the training set. If the training set doesn’t contain any hot documents, it is unlikely that any hot documents in the rest of the document set will get high scores. An algorithm may have high confidence if the document contains a particular word with high frequency (number of occurrences divided by the number of words in the document). If presence of the word “fraud” is seen as a good indicator that the document is relevant, an algorithm may take a document using the word “fraud” frequently to have a high probability of relevance, and therefore assign a high score. It will assign a higher score to a document saying “Fraud is not tolerated here. Fraud will be reported to the police.” than to a document saying “If we get caught, we’re going to go to jail for fraud.”
This diagram gives a reasonable, but simplified, picture of what a training set might look like to a predictive coding classification algorithm:
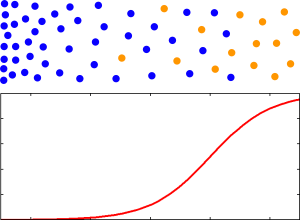 The dots along the top represent documents that were reviewed by a human, with relevant documents shown in orange and non-relevant documents shown in blue. As you move from left to right some feature that is a good indicator of relevance (meaning that it helps in distinguishing relevant documents from non-relevant documents) increases in frequency. For example, the frequency of a word like “fraud” might increase as you go to the right. The vertical position of the documents doesn’t matter — you can think of vertical position as specifying the frequency of a feature that is not a good indicator of relevance (e.g. the frequency of the word “office”). The algorithm is commonly given only yes/no values for relevance as input, so it has no way of knowing whether some of the orange documents are more important than others. What it does know is that a document has a higher probability of being relevant, assuming that the training set is representative of the document set in general, if it is farther to the right. The algorithm might even estimate the probability of a document being relevant based on how far to the right it is, as shown by the red curve below the dots.
The dots along the top represent documents that were reviewed by a human, with relevant documents shown in orange and non-relevant documents shown in blue. As you move from left to right some feature that is a good indicator of relevance (meaning that it helps in distinguishing relevant documents from non-relevant documents) increases in frequency. For example, the frequency of a word like “fraud” might increase as you go to the right. The vertical position of the documents doesn’t matter — you can think of vertical position as specifying the frequency of a feature that is not a good indicator of relevance (e.g. the frequency of the word “office”). The algorithm is commonly given only yes/no values for relevance as input, so it has no way of knowing whether some of the orange documents are more important than others. What it does know is that a document has a higher probability of being relevant, assuming that the training set is representative of the document set in general, if it is farther to the right. The algorithm might even estimate the probability of a document being relevant based on how far to the right it is, as shown by the red curve below the dots.
When the algorithm is asked to make predictions for a document that has not been reviewed by a human, it can measure the frequency of the indicator word (e.g. “fraud”) for the document and spit out the probability estimate that was generated from the training data. Rather than the actual probability estimate, it could use any monotonic function of the probability estimate (i.e. any quantity that increases when the probability increases) as the relevance score.
Documents with a high relevance score are the documents that have the highest probability (as far as the algorithm can tell) of being relevant. They are the documents that the algorithm is confident are relevant. They are the low-hanging fruit if your goal is to find the largest number of relevant documents without wading through a lot of non-relevant documents. They are not necessarily the most informative or most relevant documents. Rather, they are the relevant documents that are easiest for the algorithm to find. Documents with a very low relevance score are the documents that have the lowest probability of being relevant. What about the documents between those extremes? Those are the documents where the algorithm just isn’t sure. The features that the algorithm uses to separate the documents that are relevant from those that aren’t simply don’t work well for those documents. Actual relevance for those documents may depend on words that the algorithm isn’t paying attention to, or it may depend on a very specific ordering of the words when the algorithm is ignoring word order, or it may depend on a subtle contextual detail that only a human could appreciate.
The relevance score indicates how well the algorithm understands the document based on experience with other similar documents in the training set, so it is clearly specific to the algorithm and is not an inherent property of the document. Different algorithms will do a better/worse job of finding features that separate relevant documents from non-relevant documents, and different algorithms will do a better/worse job of modeling the probability of a document being relevant based on experience with the training set. All of these things will impact the precision-recall curve.
At this point, the difference between an algorithm that produces a relevance score and an algorithm that produces a yes/no relevance prediction should be clear. An algorithm that produces a score “knows what it doesn’t know,” while an algorithm that produces a yes/no doesn’t (or it knows and refuses to tell you). An algorithm that produces a score tells you which documents it is uncertain about. You could always convert a score to a yes/no by picking an arbitrary cutoff for the score, say 50, and proclaiming that only documents reaching that threshold are predicted to be relevant. So, two documents with scores of 49 and 50, which might even be near-dupes, would be predicted to be non-relevant and relevant respectively. That should make the arbitrariness of a yes/no result clear. Whenever you produce a yes/no result, even if it doesn’t involve an explicit score and cutoff, there will be the possibility that two very similar documents will generate completely different outputs because a binary output does not allow the similarity of the inputs to be expressed.
If you are the producing party in a case, and you plan to review all documents before producing them, you can produce the largest number of responsive documents (one can certainly debate whether that is the most appropriate goal) at the lowest cost by ordering the documents by the relevance score to bring the low-hanging fruit to the top. As you work your way down the document list, you will have to review more and more non-responsive documents for each responsive document you hope to find (think about going from right to left in the diagram above). As described in my previous article, you can compute how many documents you’ll need to review to achieve a desired level of recall using the precision-recall curve, and the appropriate stopping point (recall level) for the case can be determined from proportionality and the cost curve. If the algorithm produces a yes/no prediction instead of a relevance score, you won’t have a precision-recall curve, just a single precision-recall point. The stopping point will be dictated by the software rather than proportionality and the value of the case.
Sidenote: The diagram shows the simplest possible example to illustrate the ideas in the article. It is, in fact, so simple that it would apply equally well to a keyword search for a single word if the search algorithm used word frequency to order the search results (many do). A more realistic example would involve many dimensions and relevance score contours that could not be achieved with a search engine, but the idea still holds — middling scores should occur for documents that reside in areas of the document space where relevant and non-relevant documents aren’t well-separated.