
Understandably, vendors of predictive coding software want to show off numbers indicating that their software works well. It is important for users of such software to avoid drawing wrong conclusions from performance numbers.
Consider the two precision-recall curves below (if you need to brush up on the meaning of precision and recall, see my earlier article):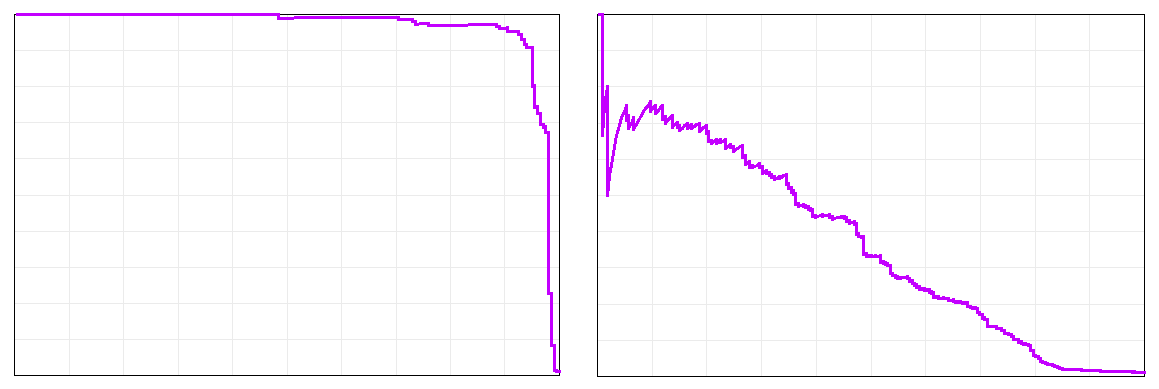
The one on the left is incredibly good, with 97% precision at 90% recall. The one on the right is not nearly as impressive, with 17% precision at 70% recall, though you could still find 70% of the relevant documents with no additional training by reviewing only the highest-rated 4.7% of the document population (excluding the documents reviewed for training and testing).
Why are the two curves so different? They come from the same algorithm applied to the same document population with the same features (words) analyzed and the exact same random sample of documents used for training. The only difference is the categorization task being attempted, i.e. what type of document we consider to be relevant. Both tasks have nearly the same prevalence of relevant documents (0.986% for the left and 1.131% for the right), but the task on the left is very easy and the one on the right is a lot harder. So, when a vendor quotes performance numbers, you need to keep in mind that they are only meaningful for the specific document set and task that they came from. Performance for a different task or document set may be very different. Comparing a vendor’s performance numbers to those from another source computed for a different categorization task on a different document set would be comparing apples to oranges.
Fair comparison of different predictive coding approaches is difficult, and one must be careful not to extrapolate results from any study too far. As an analogy, consider performing experiments to determine whether fertilizer X works better than fertilizer Y. You might plant marigolds in each fertilizer, apply the same amount of water and sunlight, and measure plant growth. In other words, keep everything the same except the fertilizer. That would give a result that applies to marigolds with the specific amount of sunlight and water used. Would the same result occur for carrots? You might take several different types of plants and apply the same experiment to each to see if there is a consistent winner. What if more water was used? Maybe fertilizer X works better for modest watering (it absorbs and retains water better) and fertilizer Y works better for heavy watering. You might want to present results for different amounts of water so people could choose the optimal fertilizer for the amount of rainfall in their locations. Or, you might determine the optimal amount of water for each, and declare the fertilizer that gives the most growth with its optimal amount of water the winner, which is useful only if gardeners/farmers can adjust water delivery. The number of experiments required to cover every possibility grows exponentially with the number of parameters that can be adjusted.
Predictive coding is more complicated because there are more interdependent parts that can be varied. Comparing classification algorithms on one document set may give a result that doesn’t apply to others, so you might test on several document sets (some with long documents, some with short, some with high prevalence, some with low, etc.), much like testing fertilizer on several types of plants, but that still doesn’t guarantee that a consistent winner will perform best on some untested set of documents. Does a different algorithm win if the amount of training data is higher/lower, similar to a different fertilizer winning if the amount of water is changed? What if the nature of the training data (e.g., random sample vs. active learning) is changed? The training approach can impact different classification algorithms differently (e.g., an active learning algorithm can be optimized for a specific classification algorithm), making the results from a study on one classification algorithm inapplicable to a different algorithm. When comparing two classification algorithms where one is known to perform poorly for high-dimensional data, should you use feature selection techniques to reduce the dimensionality of the data for that algorithm under the theory that that is how it would be used in practice, but knowing that any poor performance may come from removing an important feature rather than from a failure of the classification algorithm itself?
What you definitely should not do is plant a cactus in fertilizer X and a sunflower in fertilizer Y and compare the growth rates to draw a conclusion about which fertilizer is better. Likewise, you should not compare predictive coding performance numbers that came from different document sets or categorization tasks.



