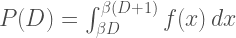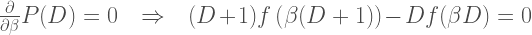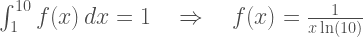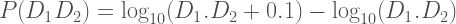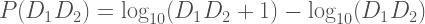This article examines Dr. SHIVA Ayyadurai’s claims that the shape of some graphs generated from Michigan voting data suggests that the vote count was being fraudulently manipulated. To be clear, I am not making any claim about whether or not fraud occurred — I’m only addressing whether Dr. Shiva’s arguments about curve shape are convincing.
I’ll start by elaborating on some tweets I wrote (1, 2, 3) in response to Dr. Shiva’s first video (twitter, youtube) and I’ll respond to his second video (twitter, youtube) toward the end. Dr. Shiva makes various claims about what graphs should look like under normal circumstances and asserts that deviations are a signal that fraud has occurred. I use a little math to model reasonable voter behavior in order to determine what should be considered normal, and I find Dr. Shiva’s idea of normal to be either wrong or too limited. The data he considers to be so anomalous could easily be a consequence of normal voter behavior — there is no need to talk about fractional votes or vote stealing to explain it.
Here is a sample ballot for Michigan. Voters have the option to fill in a single box to vote for a particular party for all offices, referred to as a straight-party vote. Alternatively, they can fill in a box for one candidate for each office, known as an individual-candidate vote. In his first video, Dr. Shiva compares the percentage of straight-party votes won by the Republicans to the percentage of individual-candidate votes won by Trump and claims to observe patterns that imply some votes for Trump were transferred to Biden in a systematic way by an algorithm controlling the vote-counting machine.
Let’s start with some definitions:
x = proportion of straight-party votes going to the Republican party for a precinct
i = proportion of individual-candidate presidential votes going to Trump for a precinct
y = i – x
I’ll be using proportions (numbers between 0.0 and 1.0) instead of percentages to avoid carrying around a lot of factors of 100 in equations. I assume you can mentally convert from a proportion (e.g., 0.25) to the corresponding percentage (e.g., 25%) as needed. Equations are preceded by a number in brackets (e.g., [10]) to make it easy to reference them. You can click any of the graphs to see a larger version.
Dr. Shiva claims there are clear signs of fraud in three counties: Oakland, Macomb, and Kent. The data for each precinct in Kent County is available here (note that their vote counts for Trump and Biden include both straight-party and individual-candidate votes, so you have to subtract out the straight-party votes when computing i). If we represent each precinct as a dot in a plot of y versus x, we get (my graph doesn’t look as steep as Dr. Shiva’s because his vertical axis is stretched):

Dr. Shiva claims the data should be clustered around a horizontal line (video 1 at 22:08) and provides drawings of what he expects the graph to look like:


He asserts that the downward slope of the data for Kent County implies an algorithm is being used to switch Trump votes to Biden in the vote-counting machine. In precincts where there are more Republicans (large x), the algorithm steals votes more aggressively, causing the downward slope. As a sanity check on this claim, let’s look at things from Biden’s perspective instead of Trump’s. We define a set of variables similar to the ones used above, but put a prime by each variable to indicate that it is with respect to Biden votes instead of Trump votes:
x‘ = proportion of straight-party votes going to the Democrat party for a precinct
i‘ = proportion of individual-candidate presidential votes going to Biden for a precinct
y‘ = i’ – x’
Here is the graph that results for Kent County:

If the Biden graph looks like the Trump graph just flipped around a bit, that’s not an accident. Requiring proportions of the same whole to add up to 1 and assuming third-party votes are negligible (the total for all third-party single-party votes averages 1.5% with a max of 4.3% and for individual-candidate votes the average is 3.3% with a max of 8.6%, so this assumption is a pretty good one that won’t impact the overall shape of the graph significantly) gives:
[1] x + x’ = 1
[2] i + i’ = 1
which implies:
[3] x’ = 1 – x
[4] y’ = –y
Those equations mean we can find an approximation to the Biden graph by flipping the Trump graph horizontally around a vertical line x = 0.5 and then flipping it vertically around a horizontal line y = 0, like this (the result in the bottom right corner is almost identical to the graph computed above with third-party candidates included):

As a result, if the Trump data is clustered around a straight line, the Biden data must be clustered around a straight line with the same slope but different y-intercept, making it appear shifted vertically.
The Biden graph slopes downward, so by Dr. Shiva’s reasoning an algorithm must be switching votes from Biden to Trump, and it does so more aggressively in precincts where there are a lot of Democrats (large x’). Wait, is Biden stealing from Trump, or is Trump stealing from Biden? We’ll come back to this question shortly.
Dr. Shiva shows Oakland County first in his video. I made a point of showing you Kent County first so you could see it without being biased by what you saw for Oakland County. This is Dr. Shiva’s graph of Trump votes for Oakland:

The data looks like it could be clustered around a horizontal line for x < 20%. Dr. Shiva argues that the algorithm kicks in and starts switching votes from Trump to Biden only for precincts having x > 20%.
We can look at it (approximately) in terms of Biden votes by flipping the Trump graph twice using the procedure outlined in Figure 5:

The data in the Biden graph appears to be clustered around a horizontal line for x’ > 80%, which is expected since it corresponds to x < 20% in the Trump graph. If you buy the argument that the data should follow a horizontal line when it is unmolested by the cheating algorithm, this pair of graphs finally answers the question of who is stealing votes from whom. Since the y-values for x > 20% are less than the y-values in the x < 20% (“normal”) region, Trump is being harmed in the cheating region. Consistent with that, Biden’s y’-value for x’ > 80% (the “normal” region) is about -5% and y’ is larger in the x’ < 80 region where the cheating occurs, so Biden benefits from the cheating. Trump is the one losing votes and Biden is the one gaining them, if you buy the argument about the “normal” state being a horizontal line.
Dr. Shiva draws a kinked line through the data for Kent (video 1 at 36:20) and Macomb (video 1 at 34:39) Counties with a flat part when x is small, similar to his graph for Oakland County, but if you look at the data without the kinked line to bias your eye, you probably wouldn’t think a kink is necessary — a straight line would fit just as well, which leaves open the question of who is taking votes from whom for those two counties.
Based on the idea that the data should be clustered around a horizontal line, Dr. Shiva claims that 69,000 Trump votes were switched to Biden by the algorithm in the three counties (video 1 at 14:00 or this tweet).
All claims of cheating, who is stealing votes from whom, and the specific number of votes stolen, are riding on the assumption that the data has to be clustered around a horizontal line in the graphs if there is no cheating. That critical assumption deserves the utmost scrutiny, and you’ll see below that it is not at all reasonable.
In Figure 8 below it is impossible for the data point for any precinct to lie in one of the orange regions because that would imply Trump received either more than 100% or less than 0% of the individual-candidate votes. For example, if x = 99%, you cannot have y=10% because that implies Trump received 109% of the individual-candidate votes (i = y + x). Any model that gives impossible y-values for plausible x-values must be at least a little wrong. The only horizontal line that doesn’t encroach on one of the orange region is y = 0.

Before we get into models of voter behavior that are somewhat realistic, let’s consider the simplest model possible that might mimic Dr. Shiva’s thinking to some degree. If the individual-candidate voters are all Republicans and Democrats in the exact same proportions as in the pool of single-party voters, and all Republicans vote for Trump while all Democrats vote for Biden, we would expect i = x and therefore y = 0 (i.e., the data would cluster around a horizontal line with y = 0). Suppose 10% of Democrats in the individual-candidate pool decide to defect and vote for Trump while all of the Republicans vote for Trump. That would give i = x + 0.1 * (1 – x). The factor of (1 – x) represents the number of Democrats that are available to defect (there are fewer of them toward the right side of the graph). That gives y = 0.1 – 0.1 * x, which is a downward-sloping line that starts at y = 10% at the left edge of the graph and goes down to y = 0% at the right edge of the graph, thus never encroaching on the orange region in Figure 8. Dr. Shiva also talks about the possibility of Republicans defecting away from Trump (video 1 at 44:43) and shows data clustered around a horizontal line at y = -10%. Again applying the simplest possible thinking, if 10% of Republicans defected away from Trump we would have i = 0.9 * x, so y = -0.1 * x. Data would again cluster around a downward-sloping line. This time it would start at y = 0% at the left edge and go down to y = -10% at the right edge. The only possible horizontal line is y = 0. Everything else wants to slope downward.
The model described in the previous paragraph is really too simple to describe reality in most situations. There are no Independent voters in that model, and it assumes the individual-candidate voting pool has the same percentage of Republicans as the straight-party pool. In reality, individual-candidate voters shouldn’t be expected to be just like straight-party voters — they choose to vote that way for a reason. Below I lay out some simple models for how different types of voters might reasonably be expected to behave. The focus is on determining how things depend on x so we can compute the shape of the y versus x curve. After describing different types of individual-candidate voters, I explain how to combine the different types into a single model to generate the curve around which the data is expected to cluster. If the model accommodates the data that is observed, there is no need to talk about cheating or how it would impact the graphs — you cannot prove cheating (though it may still be occurring) if the graph is consistent with normal voter behavior. In the following, the equations relating x to i or y apply to the curves around which the data clusters, not the position of any individual precinct.
Type 1 (masochists): Imagine the individual-candidate voters are actually Republicans voting for Trump or Democrats voting for Biden, but they choose not to use the straight-party voting option for some reason. Perhaps a Republican intended to vote for the Republican candidate for every office, but didn’t notice the straight-party option, or perhaps he/she is a masochist who enjoys filling in lots of little boxes unnecessarily (I’ll call all Type 1 people masochists even though it really only applies to a subset of them because I can’t think of a better name). Maybe a Republican votes for the Republican candidate for every office except dog catcher because his/her best friend is the Democratic candidate for that office (can Republicans and Democrats still be friends?). With this model, the number of individual-candidate voters that vote for Trump is expected to be proportional to the number of Republicans. We don’t know how many Republicans there are in total, but we can assume the number is proportional to x, giving A * x individual-candidate votes for Trump where A is a constant (independent of x). Similarly, Biden would get A’ * (1 – x) individual-candidate votes. If all individual-candidate voters are of this type, we would have:
[5] i = A * x / [A * x + A’ * (1-x)]
If the same proportion of Democrats are masochists as Republicans, A = A’, we have i = x, so y = i – x gives y = 0, meaning the data will be clustered around the horizontal line y = 0, which is consistent with the view Dr. Shiva espouses in his first video. This model does not, however, support data being clustered around a horizontal line with the y-value being different from zero. If A is different from A’, the data will be clustered around a curve as shown in Figure 9 below.

Type 2 (Independents): Imagine the individual-candidate voters are true Independent voters. Perhaps they aren’t fond of either party, so they vote for the presidential candidate they like the most (or hate the least) and vote for the opposite party for any congressional positions to keep either party from having too much power, necessitating an individual-candidate vote instead of a straight-party vote. Maybe they vote for each candidate individually based on their merits and the candidates they like don’t happen to be in the same party. How should the proportion of Independents voting for Trump depend on x? Roughly speaking, it shouldn’t. The value of x tells what proportion of a voter’s neighbors are casting a straight-party vote for the Republicans compared to the Democrats. The Independent voter makes his/her own decision about who to vote for. The behavior of his/her neighbors should have little impact (perhaps they experience a little peer pressure or influence from political yard signs). Democrats are expected to mostly vote for Biden regardless of who their neighbors are voting for. Republicans are expected to mostly vote for Trump regardless of who their neighbors are voting for. Likewise, Independents are not expected to be significantly influenced by x. If all individual-candidate voters are of this type, we have i = b, where b is a constant (no x dependence), so y = b – x, meaning the data would be clustered around a straight line with slope -1 as shown in Figure 10 below.

Type 3 (defectors): In this case we have some percentage of Democrats defecting from their party to vote for Trump. Likewise, some percentage of Republicans defect to vote for Biden. This is mathematically similar to Type 1, except Trump now gets votes in proportion to (1 – x) instead of x, reflecting the fact that his individual-candidate votes increase when there are more Democrats available to defect. If all individual-candidate voters are of this type, we have:
[6] i = C * (1 – x) / [C * (1 – x) + C’ * x)]
If the same proportion of Democrats defect as Republicans, C = C’, we have i = 1 – x, so y = 1 – 2 * x, causing the data to cluster around a straight line with slope of -2. If C and C’ are different, the data will be clustered around a curve as shown in Figure 11 below.

Realistically, the pool of individual-candidate voters should have some amount of all three types of voters described above. To compute i, and therefore y, we need to add up the votes (not percentages) from various types of voters. We’ll need some additional notation:
NSP = total number of straight-party voters (all parties) for the precinct (this is known)
NIC = total number of individual-candidate voters (this is known)
I = number of Independent (Type 2) voters (not known)
v = number of individual-candidate votes for Trump
v’ = number of individual-candidate votes for Biden
The number of individual-candidate votes for Trump would be:
[7] v = A * x * NSP + b * I + C * (1 – x) * NSP
and the number for Biden would be:
[8] v’ = A’ * (1 – x) * NSP + (1 – b) * I + C’ * x * NSP
The total number of individual-candidate voters comes from adding those two expressions and regrouping the terms:
[9] NIC = v + v’ = A’ * NSP + (A – A’) * x * NSP + I + C * NSP + (C’ – C) * x * NSP
The last equation tells us that if we divide the number of individual-candidate votes by the number of straight-party votes for each precinct, NIC / NSP, and graph it as a function of x, we expect the result to cluster around a straight line (assuming I / NSP is independent of x). If the behavior of Republicans and Democrats was exactly the same (A = A’ and C = C’), the straight line would be horizontal. Here is the graph:

The line was fit using a standard regression. The fact that it slopes strongly upward tells us Republicans and Democrats do not behave the same. A larger percentage of Republicans cast individual-candidate votes than Democrats, so Republican-heavy precincts (large x) have a lot more individual-candidate votes. The number of straight-party votes also increases with x, but not as dramatically, suggesting that Republican precincts either tend to have more voters or tend to have higher turnout rates. By requiring our model to match the straight line in the figure above, we can remove two degrees of freedom (corresponding to the line’s slope and intercept) from our set of six unknown parameters (A, A’, b, I/NSP, C, C’).
We compute y = i – x = v / NIC – x. Fitting the y versus x graph can remove two more degrees of freedom. To completely nail down the parameters, we need to make an assumption that will fix two more parameters. Since the slope of the y versus x graph for Kent County lies between 0 (Type 1 voters) and -1 (Type 2 voters), we will probably not do too much damage by assuming there are no Type 3 voters, so C = 0 and C’ = 0. We are now in a position to determine all of the remaining parameters by requiring the model to fit the NIC / NSP versus x data from Figure 12 and the y versus x data, giving:
[10] A = 0.5, A’ = 0.09, b = 0.073, I / NSP = 0.41, C = 0, C’ = 0

The curve generated by the model is not quite a straight line — it shows a little bit of curvature in the graph above. That curvature is in good agreement with the data. If NIC depends on x, as it will when A is different from A’ or when C is different from C’, there will be some curvature to the y versus x graph. In other words, when there are differences between the behavior of Republicans and Democrats this simple model will generate a y versus x graph having curvature. When there is no difference in behavior, it gives a straight line.
The relatively simple model seems to fit the data nicely. The remaining question is whether the parameter values are reasonable. If they are, we can conclude that the observed data is consistent with the way we expect voters to behave, so the graph does not suggest any fraud. If the parameter values are crazy, there may be fraud or our simple model of voter behavior may be inadequate. It will be easier to assess the reasonableness of our parameters if they are proportions (or percentages), which A, A’, C, and C’ aren’t. We would like to know the proportion of Republicans (or Democrats) voting in a particular way. We start by writing out the number of Republicans, R, according to the model as just the sum of straight-party Republican voters plus individual-candidate Republicans voting for Trump (the A term) and defector Republicans voting for Biden (the C’ term). A similar approach determines the number of Democrats.
[11] R = x * NSP + A * x * NSP + C’ * x * NSP
[12] D = (1 – x) * NSP + A’ * (1 – x) * NSP + C * (1 – x) * NSP
We now define new parameters:
a = the proportion of Republicans voting for Trump by individual-candidate ballot
a’ = the proportion of Democrats voting for Biden by individual-candidate ballot
c = the proportion of Democrats that defect to vote for Trump
c’ = the proportion of Republicans that defect to vote for Biden
[13] a = A * x * NSP / R = A / (1 + A + C’)
[14] a’ = A’ / (1 + A’ + C)
[15] c = C * (1 – x) * NSP / D = C / (1 + A’ + C)
[16] c’ = C’ / (1 + A + C’)
In this more convenient (for understanding, but not for writing equations) parameterization we have:
[17] a = 0.33, a’ = 0.083, b = 0.073, I / NSP = 0.41, c = 0, c’ = 0
In words, 33% of Republicans use an individual-candidate ballot to vote for Trump instead of a straight-party vote. Only 8.3% of Democrats use an individual-candidate ballot to vote for Biden instead of a straight-party vote. Only 7.3% of Independents voted for Trump, with the other 92.7% voting for Biden. The number of Independent voters is, on average, 41% of the total number of straight-party voters, which means Independents are considerably less than 41% of all voters (since some Republicans and Democrats don’t vote straight-party). Some values seem a little extreme, such as only 7.3% of Independents voting for Trump, but none are completely pathological. Parameter values would shift around a bit if we allowed non-zero values for c and c’ (defectors). It is worth noting that when I talk about the number of Republicans, Democrats, and Independents, I am not talking about the number of people that registered that way — I base those numbers on their behavior (i.e., the assumption that the number of Republicans is proportional to x). With all of those things in mind, I think it is safe to say that the graphs are consistent with reasonable expectations of voter behavior (no need for fraud to explain the shape), but the parameter values shouldn’t be taken too seriously.
The simple models above show a wide range of possible slopes for the data, going from 0 to -2 (when parameter values generate a straight line). A horizontal line (0 slope) requires there to be no Independent voters and no defectors. Furthermore, it requires the percentage of Republicans and Democrats choosing to use individual-candidate voting to be exactly the same (A = A’). The assumption that data should cluster around a horizontal line is really an extreme assumption that requires things to be perfectly balanced. Claiming that deviation from a horizontal line is a sign of fraud is like observing a coin toss come up heads or tails and proclaiming there must be cheating because a fair coin would have landed on its edge. Dr. Shiva’s videos never show an example of real data clustering around a horizontal line. He does show a graph for Wayne County (video 1 at 38:02) and claims it lacks the algorithmic cheating seen in the other three counties, but all of the data for Wayne County is confined to such a small range of x values that you can’t conclude much of anything about the slope.
Dr. Shiva’s second video starts by talking about signal detection and the importance of distinguishing the “normal state” from an “abnormal state” in various contexts. At 50:08 he states: “What we didn’t share in the first video is what is a normal state?” This would be a good time to scroll up and take a second look at Figure 2, which is a screen shot from the first video. He now claims the normal state would be to have the data in the y versus x graph clustered around a parabola. Horizontal lines are gone. Claims about the number of votes stolen based on expecting the data to follow a horizontal line are forgotten. He provides this graph from another election, Jeff Sessions for Senate in 2008, as his first example of the normal state:

The graph has negative curvature, meaning it is shaped like an upside down bowl. Positive curvature would be shaped like a bowl that is right-side up. He provides two more examples that also have negative curvature. He proclaims that there must be cheating in Oakland, Macomb, and Kent counties, not because they slope downward, but because they are too straight. As before, I’m going to flip the graph twice to see what it would look like in terms of Jeff Sessions’ competitor’s votes:

The flipped graph has positive curvature. If negative curvature is normal, positive curvature must also be normal. A straight line is just zero curvature. If some amount of negative curvature is normal and a similar amount of positive curvature is normal, it would be weird, but not impossible, for curvature values in between to be abnormal (note that this is a very different argument from what I said about the horizontal line y = 0, because that case was at the extreme end of the spectrum of possibilities, not in the middle). Anyway, I already showed a reasonable model of voter behavior accommodates both significant curvature (Figure 9) and straight lines (Figures 10 and 11), and I showed that Kent County has a little bit of curvature (Figure 13).
Dr. Shiva explains his claim that the normal state should be a parabola using this graph:

He claims there should be three different behaviors, resulting in a parabola, because there are three regions representing different types of voters. I think the labeling of the voters along the bottom of Figure 16 reveals some confused thinking. Why are there Independents in the middle section? Why does the quantity of Independents depend on the percentage of straight-party voters that vote Republican (i.e., the value of x)? Do Independents move out of the neighborhood if the number of Trump signs and Biden signs in the neighborhood are too far out of balance, or is the number of Independents really a separate variable (a third dimension, with Democrats and Republicans being the other two)? In my simple model above, which could certainly be wrong, curvature comes from differences in behavior between Republicans and Democrats (Figure 9), whereas more Independents makes the curve straighter (Figure 10).
Dr. Shiva introduces some new graphs in the second video at 1:02:21 that he claims are additional evidence of problems in the three counties. Instead of working with percentages, he uses the raw number of votes. He graphs the number of individual-candidate votes for Trump, v, versus the number of single-party votes for the Republicans, w. Similarly, he graphs the number of individual-candidate votes for Biden, v’, versus the number of single-party votes for the Democrats, w’. He overlaid them on the same graph, but I’ll separate them for clarity. Here are the results for Kent County:


I fit the lines with a standard regression because it is not quite possible to generate predicted curves using our model. Dr. Shiva’s concern is that the two graphs are so different. Specifically, the data in the Trump graph in Figure 17 is very tightly clustered around the straight line, whereas the Biden graph in Figure 18 shows the data to be much more spread out. We’ll return to that point after talking a bit about how the graphs relate to the model we used on the Kent County data earlier.
Expressions for v and v’ for our model were given earlier in Equations [7] and [8]. Noting that w = x * NSP, and w’ = (1 – x) * NSP, we can write v and v’ in terms of w and w’:
[18] v = A * w + b * I
[19] v’ = A’ * w’ + (1 – b) * I
The problem with graphing the model’s prediction is that I is a function of x with positive slope (our model treated I / NSP as a constant with value 0.41, but NSP itself depends on x as noted earlier), so we can’t use Equations [18] and [19] to graph the model curve. We can do some basic checks for consistency with our model, however. The Independent voter term contributes very little to v because b is small (Trump only gets 7.3% of the Independent vote in our model). So the slope of the v versus w curve should be a little more than A, which is 0.5, and the line in Figure 17 has a slope of 0.52. The slope of the v’ versus w’ curve should be A’, which is 0.09, plus (1 – b) times whatever I contributes to the slope. The line in Figure 18 has a slope of 0.26, which is larger than 0.09, as required, but it is unclear whether it is too large. The ratio of the y-intercepts for the lines in Figures 18 and 17 should be (1 – b) / b, which is 12.7, compared to 13.8 for the lines fitted to the data in the graphs.
While our model doesn’t say anything quantitative about the spread expected for the data, it can give us some qualitative guidance. The source of most of the individual-candidate votes for Trump is Republicans that choose to vote for individual candidates (masochists) rather than straight party. He gets only 7.3% of the Independent vote. By contrast, Biden gets a lot of his individual-candidate votes from Independents. This is reflected in Biden’s graph having a relatively large y-intercept. He gets around 200 votes even for precincts where there are no Democrats around to vote for him (w’ = 0 implies no straight-party Democrat voters and presumably very few individual-candidate voting Democrats) because he has 92.7% of the Independents.
We expect 33% of Republicans to vote for Trump with an individual-candidate ballot on average. We wouldn’t be surprised if some precincts have 25% or 40% instead of 33%, but we wouldn’t expect something wild like 10% or 80%, so the data points are expected to stay pretty close to the line for Trump. On the other hand, Biden gets a lot of votes from Independents and the number of Independents is expected to vary a lot between precincts. The number of Republicans varies a lot from precinct to precinct (based on x ranging from 10% to 80%), so it is reasonable to expect similar variation in the number of Independents, causing a large spread in Biden’s graph. The differences between Figures 17 and 18 are not surprising in light of the very different nature of the individual-candidate voters for Trump and Biden, which we already knew about due to the slope of Figure 12.
In summary, Dr. Shiva is right when he says it is important to distinguish normal behavior from abnormal behavior when trying to identify manipulated data. Where he comes up short is in determining what normal behavior should look like. If the data is consistent with a reasonable model of human behavior, it is normal and cannot be considered evidence of fraud. In his first video he claims a horizontal line is the only normal state, but in reality a horizontal line other than y = 0 would be highly abnormal. His second video gets closer to reality when claiming the normal state should be a parabola, but that is too limited — data with little or no curvature is perfectly reasonable, too.










 Gaylord National Resort & Convention Center in National Harbor, Maryland. I wasn’t able to attend the sessions (so I don’t have any notes to share) because I was manning the Clustify booth in the exhibit hall, but I did take a lot of photos which you can view
Gaylord National Resort & Convention Center in National Harbor, Maryland. I wasn’t able to attend the sessions (so I don’t have any notes to share) because I was manning the Clustify booth in the exhibit hall, but I did take a lot of photos which you can view