
When you try to quantify how similar near-duplicates are, there are several subtleties that arise. This article looks at three reasonable, but different, ways of defining the near-dupe similarity between two documents. It also explains the popular MinHash algorithm, and shows that its results may surprise you in some circumstances. Near-duplicates are documents that are nearly, but not exactly, the same. They could be different revisions of a memo where a few typos were fixed or a few sentences were added. They could be an original email and a reply that quotes the original and adds a few sentences. They could be a Microsoft Word document and a printout of the same document that was scanned and OCRed with a few words not matching due to OCR errors. For e-discovery we want to group near-duplicates together, rather than discarding near-dupes as we might discard exact duplicates, since the small differences between near-dupes of responsive documents might reveal important information. Ideally, the document review software will display the near-dupes side-by-side with common text highlighted, as shown in the figure above, so reviewers don’t waste time reading the same text over and over. Typically, you’ll need to provide the near-dupe software with a threshold indicating how similar you want the documents to be in order for them to be grouped together. So, the software needs a concrete way to generate a number, say between 0 and 100%, measuring how similar two documents are. In this article we’ll look at some sensible ways of defining the near-dupe similarity.
Near-duplicates are documents that are nearly, but not exactly, the same. They could be different revisions of a memo where a few typos were fixed or a few sentences were added. They could be an original email and a reply that quotes the original and adds a few sentences. They could be a Microsoft Word document and a printout of the same document that was scanned and OCRed with a few words not matching due to OCR errors. For e-discovery we want to group near-duplicates together, rather than discarding near-dupes as we might discard exact duplicates, since the small differences between near-dupes of responsive documents might reveal important information. Ideally, the document review software will display the near-dupes side-by-side with common text highlighted, as shown in the figure above, so reviewers don’t waste time reading the same text over and over. Typically, you’ll need to provide the near-dupe software with a threshold indicating how similar you want the documents to be in order for them to be grouped together. So, the software needs a concrete way to generate a number, say between 0 and 100%, measuring how similar two documents are. In this article we’ll look at some sensible ways of defining the near-dupe similarity.
The first two methods for measuring similarity involve identifying matching chunks of text in the documents. Suppose we have two documents with the shorter document having length S, measured by counting words (it would be more proper to say “tokens” instead of “words” since we might count numbers appearing in the text, too), and the longer document having length L. We identify substantial chunks of text (not just an isolated word or two) that the two documents have in common, and find the number of words in the common text that the documents share to be C. We could define the near-dupe similarity of the two documents to be (SL is the similarity, not to be confused with S, the length of the shorter document):

Since the number of words the documents have in common, C, cannot be larger than the number of words in either document, the ratio C/L is between 0 and 1 (the ratio C/S is also between 0 and 1, but you could have C/S=1 for documents of wildly different lengths if the short document is contained within the long one, so we don’t consider C/S to be a good measure for near-dupes, although it might be useful for other purposes). We can multiply by 100 to turn it into a percentage. Suppose we measure SL to be 80% for a pair of documents. That tells us that if we read either document we’ve read at least 80% of the content from the other document, so SL has a very practical meaning when it comes to making decisions about which documents you need to review. SL does have a shortcoming, however. It doesn’t depend on the length of the shorter document at all. If three documents have the same text in common, the value of SL will be the same when comparing the longest document to either of the two shorter ones, giving no hint that one of the shorter documents may contain more unique (not shared with the longest document) text than the other.
A different way of measuring the similarity is inspired by the Jaccard index from set theory:
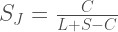
The denominator may look a little strange, but it is just the amount of unique text contained in the combination of both documents. L+S is the total amount of text, but that counts the common chunks of text shared by both documents twice, so we subtract C to compensate for that double-counting. SJ is between 0 and 1. Note that SJ ≤ SL because the denominator for SJ is never smaller than the denominator for SL. To see that, note that the denominator for SJ has an extra S–C compared to the denominator for SL, and S–C is always greater than or equal to 0 because the amount of text the documents have in common is at most the length of the shorter document, i.e. S ≥ C. So, SJ is a somewhat pessimistic measure of how much the documents have in common. Let’s look at an example:

Example 1: Highlighted text is identical, so we don’t need to read it twice during review. L=100, S=97, C=85.
In Example 1 above, there are two chunks of text that match, one highlighted in orange and the other highlighted in blue. The matching chunks are separated by a single word where a typo was corrected (“too” and “to” don’t match). We have L=100, S=97, and C=85. Using the equations above we compute the two similarity measures to be SL=85% and SJ=76%.
Example 1 was pretty straightforward. Let’s consider a more challenging example:

Example 2: The document on the right is just two copies of the document on the left pasted together.
In Example 2, the document on the right contains two copies of the text from the document on the left pasted together. Forget the formulas and answer this question: What result would you want the software to give for the near-dupe similarity of these two documents? One approach, which I will call literal matching, requires a one-to-one matching of the actual text. It would view these documents as being 50% similar because only half of the document on the right matches up with text from the document on the left (SL and SJ are equal when all of the text from the short document matches with the long document, so there is no need to specify which similarity measure is being discussed in this case). A different approach, which I will call information matching, views these documents as a 100% match because duplicated chunks of text within the same document aren’t counted since they don’t add any new information. It’s as if the second copy of the sentence in the document on the right doesn’t exist because it adds nothing new to the document. You may be thinking that Example 2 is rather contrived, but repeated text within a document can happen if spreadsheets or computer-generated reports contain the same heading repeated on many different pages. So, what do you think is the most sensible approach for e-discovery purposes, literal matching or information matching? We’ll return to this issue later.
I said earlier that we are looking for “substantial” chunks of text that match between near-dupe documents, but I wasn’t explicit about what that means. I’m going to take it to mean at least five consecutive matching words for the remainder of this article. Five is an arbitrary choice that is not necessarily optimal, but it will suffice for the examples presented.
Example 3: Two potential matching chunks of text overlap in the document on the left. L=15, S=9, C=?
In Example 3, there are two 5-word-long chunks of text that could match between the two documents, but they overlap in the document on the left. The literal matching approach would say there are 5 words in common because matching “I will need money and” takes that chunk of words off the table for any further matching, leaving only 4 words (“cigars for the mayor”) remaining, which isn’t enough for a 5-word-long match. The information matching approach would say there are 9 words in common because all of the words in the document on the left are present in the document on the right in sufficiently large chunks.
So far, we’ve focused on similarity measures that require identification of matching chunks of text, but that can be algorithmically difficult. The third approach we’ll consider bases the similarity on counting shingles, i.e. overlapping contiguous sets of words of a specific length. The shingle-counting approach allows for use of a probabilistic trick called the MinHash algorithm to reduce memory consumption and speed up the calculation. I’ve seen virtually no discussion of the near-dupe algorithms used in e-discovery, but I suspect that shingling and MinHash are used by many tools because the approach is efficient and well-known (Clustify does not use this approach). MinHash is often discussed in the context of finding near-dupes of webpages. If you did a search on Google you would not want to see hundreds copies of the same Associated Press article that was syndicated to hundreds of websites (with slightly different header/footer text on each webpage) in the results, so search engines discard near-dupes. E-discovery can involve documents that are much shorter than webpages (e.g., emails), and the goal is to group near-dupes rather than discard them, so one should not assume that algorithms or minimum similarity thresholds designed for web search engines are appropriate for e-discovery.
To see what shingles look like, here are the 5-word shingles (there are 93 of them) for the document on the left in Example 1:
| 1 | It is important to use |
| 2 | is important to use available |
| 3 | important to use available technologies |
| 4 | to use available technologies to |
| … | |
| 92 | LLP and an expert on |
| 93 | and an expert on ediscovery |
To compute the similarity, generate the shingles for the two documents being compared and count the number of shingles that are common to both documents and the total number of unique shingles across both documents and use the formula:
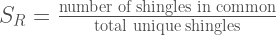
This is sometimes called the resemblance. Using 5-word shingles ensures that matching chunks of text must be at least five words long to contribute to the similarity. When counting shingles containing w words it is useful to note that a chunk of text containing N words will have N-(w-1) shingles. For the sake of comparison, it is useful to write SR in terms of the same word counts used in our other similarity measures. If the documents being compared have n chunks of text in common, we find the relationship:
![S_R = \frac{C - n\times(w-1)}{L+S-C+(n-2)\times(w-1)} = S_J \times \left[\frac{1-\frac{n\times(w-1)}{C}}{1 + \frac{(n-2)\times(w-1)}{L+S-C}}\right]](https://s0.wp.com/latex.php?latex=S_R+%3D+%5Cfrac%7BC+-+n%5Ctimes%28w-1%29%7D%7BL%2BS-C%2B%28n-2%29%5Ctimes%28w-1%29%7D+%3D+S_J+%5Ctimes+%5Cleft%5B%5Cfrac%7B1-%5Cfrac%7Bn%5Ctimes%28w-1%29%7D%7BC%7D%7D%7B1+%2B+%5Cfrac%7B%28n-2%29%5Ctimes%28w-1%29%7D%7BL%2BS-C%7D%7D%5Cright%5D&bg=ffffff&fg=444444&s=2&c=20201002)
The mess in square brackets in the rightmost part of the equation can be shown to be less than or equal to one (the proof is trivial for all cases except n=1, which is still pretty easy when you realize that C ≤ L+S–C). It is important to note that if we use the MinHash algorithm it will be impossible know n, so we cannot use the equation above to convert MinHash measurements of SR into SJ — we are stuck with SR as our similarity measure if we use MinHash. The relationship between our three similarity measures is:

Let’s compute SR for Example 1. We have n=2, w=5, L=100, S=97, and C=85, giving SR=69% (compared to SJ=76% and SL=85%). As you can see, it is important to know how the similarity is calculated when choosing a similarity threshold since values can vary significantly depending on the algorithm.
How bad can the disagreement between similarity measures be? The equation shows that SR differs from SJ most significantly when the average size of a matching hunk of text, C/n, is not much larger than the shingle size, w. Consider this example of an email and its reply:
Example 4: An email and its reply. Shows that short documents give very low similarity values when counting shingles. Also shows why it is important to group near-dupes rather than discarding them (don’t discard the confession!).
The email on the left is only five words long, so it has only one 5-word shingle. The reply on the right adds just one more word, so it has two shingles. We have a total of two unique shingles across both documents, and one shingle in common, so SR is 1/2=50% while SJ is 5/6=83%. Matching the first five words in the document on the right only counts as one common shingle, while failing to match just one word (the “Yes”) in the last five words in the document on the right counts as a non-matching shingle. This may seem like a defect, but it’s not as crazy as it might seem. Consider the contribution to the numerator of the similarity calculation for matching chunks of text of various lengths:
| Impact on Numerator of similarity | ||
|---|---|---|
| Number of Matching Words in chunk | SJ | SR |
| 3 | 0 | 0 |
| 4 | 0 | 0 |
| 5 | 5 | 1 |
| 6 | 6 | 2 |
| 7 | 7 | 3 |
| … | ||
| 100 | 100 | 96 |
For SJ, a match of four contiguous words counts for nothing, but a match of five words counts for five. Such an abrupt transition could be seen as undesirable. Shingle counting gives a much smoother transition for SR. You could view matching with 5-word shingles as saying: “We’ll count a 5-word match for something, but we really only take a match seriously if it is considerably longer than five words.”
So far, I’ve glossed over the issue of the same shingle appearing multiple times in the same document. We’ll see below that the MinHash algorithm effectively discards any duplicate shingles within a document. Recalling the terminology introduced earlier, SR with MinHash is an information matching approach, not a literal matching approach. Sort of, but not quite. Let’s return to Example 2, where the document on the right consisted of two sentences that were identical. The shingles covering the second sentence will be the same as those from the first sentence, so they won’t count, but the shingles that straddle the two sentences, starting toward the end of the first sentence and ending toward the beginning of the second sentence, are unique and will count. The document on the left contains 12 shingles that are all matched by the document on the right. The document on the right has an additional 4 shingles that straddle the boundary between the first and second sentence (e.g. “human reviewers. Predictive coding uses”), giving a total of 16 unique shingles. So SR is 12/16=75%. I challenged you earlier to decide what result you would want the software to give for Example 2, proposing 50% and 100% as two plausible values. How do you feel about 75%? If the repeated text was longer, SR would be closer to 100%.
Recall that Example 3 raised the issue of matching overlapping chunks of text. Shingle counting will happily match text that overlaps, but you should keep in mind that shingles that straddle two different matching chunks won’t match. There are 2 matching shingles in Example 3 (the text highlighted in orange and the text highlighted in blue). The document on the left has 5 shingles (including the two it has in common with document on the right) and the document on the right has 11 shingles, so SR is only 2/(5+11-2)=14%.
Finally, let’s look at the MinHash algorithm. Suppose the documents we are comparing are 3000 words long (roughly five printed pages). If we use 5-word shingles, that’s 2996 shingles per document that we need to store and compare, which would be pretty demanding if our document sent contained millions of documents. MinHash reduces the amount of data that must be stored and compared in exchange for giving a result that is only an approximation of SR. Suppose we listed all of the unique shingles from the two documents we wanted to compare and picked one of the shingles at random. What is the probability that the selected shingle would be one that is common to both documents? You would find that probability by dividing the number of common shingles by the total number of unique singles, but that’s exactly what we defined SR to be. So, we can estimate SR by estimating the probability that a randomly selected shingle is one that the documents share, which we can do by selecting shingles randomly and recording whether or not they are common to both documents; SR is then approximated by the number of common shingles we encountered divided by the number of shingles we sampled. If we sample a few hundred shingles, we’ll get an estimate for SR that is accurate to within plus or minus something like 7% (whether it is 7% or some other value depends on the number of selected samples and the desired confidence level — 200 samples at 95% confidence gives plus or minus 7%). It is tough to get the error bar on our similarity estimate much smaller than that because of the way error bars on statistically sampled values scale — to cut the error bar in half we would need four times as many samples. You can skip forward to the concluding paragraph at this point if you don’t want to read about the gory details of the MinHash algorithm; from a user’s point of view the critical thing to know is that the result is only an estimate.
MinHash uses a method of shingle sampling that is not truly random, but it is “random looking” in all ways that matter. The non-random aspect of the sampling is what allows it to reduce the amount of storage required. The MinHash algorithm computes a hash value for each shingle, and selects the shingle that has the smallest hash value. A hash function generates a number, the hash value, from a string of text in a systematic way such that the tiniest change in the text causes the hash value to be completely different. There is no obvious pattern to the hash values for a good hash function. For example, 50% of strings starting with the letter “a” will have a higher hash value than a string starting with the letter “b” — the hash value is not related to alphabetic ordering. So, selecting the shingle with minimum hash value is a “random looking” choice — it’s not at all obvious in advance which shingle will be chosen, but it is not truly random since the same hash function will always choose the same shingle. If we want to sample 200 shingles to estimate SR, we’ll need 200 different hash functions. Here is an example of hash values from two different hash functions applied to the shingles from the left document from Example 1:
| Shingle | hash1 | hash2 |
|---|---|---|
| It is important to use | 10419538473912939328824564064987594243 | 300214285342720760039511832324050800711 |
| is important to use available | 105555457340479730793594838617716806364 | 331180212539788074185988416231900930236 |
| important to use available technologies | 249315758303188756469411716170892733328 | 183376530549503672061864557636756469089 |
| to use available technologies to | 289630855896414368089666086343852687888 | 199563112601716758234064918560089655690 |
| … | ||
| LLP and an expert on | 54122989796249388067356565700270998745 | 298602506386019811335232493333781440033 |
| and an expert on ediscovery | 191435127605053759280177207148206634957 | 59413317844173777786126651204968182610 |
As you can see, the hash values have a lot of digits. For a good hash function, the probability of two different strings of text having the same hash value is extremely small (i.e. all of those digits really are meaningful, so the number of possible hash values is huge), so it’s pretty safe to assume that equal hash values implies identical text. That means we don’t need to store and compare the shingles themselves — we can store and compare the hash values instead.
The final, critical step in the MinHash algorithm is to reorganize our approach to finding the shingle (across both documents) with the minimum hash value and checking to see whether or not it is common to both documents. An equivalent approach is to find the minimum hash value for the shingles of each document separately. If those two minimum hash values (one for each document) are equal, it means the shingle having the minimum hash value across both documents exists in both documents (remember, equal hash values implies that the text is identical). If the two minimum hash values are different, it means the shingle having the minimum hash value across both documents exists in only one of the documents. This is where we get our huge performance boost. If we are comparing documents that are 3000 words long, we no longer need to store 2996 shingles (or hashes of the shingles) for each document and do a big comparison between two sets of 2996 shingles from the two documents we want to compare — we just need to compute the minimum hash value for each document once (not each time we do a comparison) and store that. When we want to compare the documents, we just compare that stored minimum hash value to see if it is equal for the two documents. So, our full procedure of “randomly” picking 200 shingles and measuring the percentage that appear in both documents to estimate SR (to within plus or minus 7%) boils down to finding the minimum hash value for each document for 200 different hash functions and storing those 200 minimum hash values, and estimating SR by counting the percentage of those 200 corresponding values that are equal for the two documents. Instead of storing the full document text, we merely need to store 200 hash values (computers store numbers more compactly than you might guess from all of the digits shown in the hash values above — those hash values only require 16 bytes of memory each).

Each document from Example 1 is represented by a circle. Shingles shown in the intersection are common to both documents. Only a subset of shingles are shown due to space constraints. Result of two hash functions being applied to shingles is shown with the last 34 digits of hash values dropped. Minimum hash value for each document is circled in orange. The first hash function selects a shingle common to both documents (“It is important to use”). The second hash function selects a shingle (“six years of experience in”) that exists only in the right document (minimum hash values for the individual documents don’t match).
As mentioned earlier, duplicated shingles within a document really only count once when using the MinHash algorithm. The duplicated shingles would just result in the same hash value appearing more than once, but that has no impact on the minimum hash value that is actually used for the calculation.
In conclusion, near-dupes aren’t as simple as one might expect, and it is important to understand what your near-dupe software is doing to ensure you are setting the similarity threshold appropriately and getting the results you expect. When doing document review with grouped near-dupes, you would like to tag all near-dupes of a non-responsive document as non-responsive without review while reviewing near-dupes of a responsive document in more detail. If misunderstandings about how the algorithm works cause the similarity values generated by the software to be higher than you expected when you chose the similarity threshold, you risk tagging near-dupes of non-responsive documents incorrectly (grouped documents are not as similar as you expected). If the similarity values are lower than you expected when you chose the threshold, you risk failing to group some highly similar documents together, which leads to less efficient review (extra groups to review). We examined three different, plausible measures of near-duplicate similarity. We found the relationship SR ≤ SJ ≤ SL, which is exemplified in our results from Example 1 where we calculated SR=69%, SJ=76% and SL=85% for a fairly normal pair of documents. Different similarity measures can disagree more significantly for short documents or documents where the same text is duplicated many times within the same document. We saw that the MinHash algorithm is an efficient way to estimate SR, but that estimate comes with an error bar. For example, an estimate of 69% means that the value is really (with 200 samples and 95% confidence) somewhere between 62% and 76%. Choosing an appropriate shingle size is important when computing SR. Large values for SR are only possible if the average chunk of matching text is significantly longer than the shingle size, which means that it is impossible to group very short (relative to the shingle size) documents (aside from exact dupes) using SR unless the minimum similarity threshold is set very low.
If you are planning to implement minhash, you can find a useful discussion on how to generate many hash functions here.
Great job, Bill! Keep them (the good stuff) coming.
Thanks again. So if you hold C equal, the more text chunks you have, the fewer shingles you will have. But if you choose to, you could just combine the text chunks. Correct? It really depends on what nuance you are looking for? Is this correct?
Hi Ben,
It is correct that if the amount of matching text, C, is fixed and n, the number of separate chunks that collectively contain that text, is increased, the number of matching shingles will decrease. However, you cannot “choose” to combine the text chunks — they are separate chunks because there are non-matching words between them. Look at the first example with the matching text highlighted in blue and orange. There are two matching chunks — the blue one and the orange one. We cannot just combine them because there is a non-matching word in between. So, returning the the first sentence in this response, keeping C fixed and increasing n would mean inserting some additional non-matching words into the middle of the blue or orange (or both) chunks to split them into a larger number of separated chunks containing the same text.
Thank you. Very thought provoking. I can clearly see the advantage of using shingling now, over the one and done chunk method. Illustrating the chunking method shows the reader why the shingling method is used. In most tutorials, the shingling method is simply introduced, without first demonstrating what inspires its use.