I recently encountered a marketing piece where a vendor claimed that their tests showed their predictive coding software demonstrated favorable performance compared to the software tested in the 2009 TREC Legal Track for Topic 207 (finding Enron emails about fantasy football). I spent some time puzzling about how they could possibly have measured their performance when they didn’t actually participate in TREC 2009.
One might question how meaningful it is to compare to performance results from 2009 since the TREC participants have probably improved their software over the past six years. Still, how could you do the comparison if you wanted to? The stumbling block is that TREC did not produce a yes/no relevance determination for all of the Enron emails. Rather, they did stratified sampling and estimated recall and prevalence for the participating teams by producing relevance determinations for just a few thousand emails.
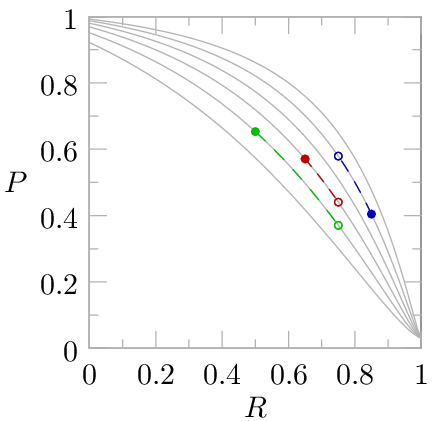
Stratified sampling means that the documents are separated into mutually-exclusive buckets called “strata.” To the degree that stratification manages to put similar things into the same stratum, it can produce better statistical estimates (smaller uncertainty for a given amount of document review). The TREC Legal Track for 2009 created a stratum containing documents that all participants agreed were relevant. It also created four strata containing documents that all but one participant predicted were relevant (there were four participants, so one stratum for each dissenting participant). There were six strata where two participants agreed on relevance, and four strata where only one of the four participants predicted the documents were relevant. Finally, there was one stratum containing documents that all participants predicted were non-relevant, which was called the “All-N” stratum. So, for each stratum a particular participant either predicted that all of the documents were relevant or they predicted that all of the documents were non-relevant. You can view details about the strata in table 21 on page 39 here. Here is an example of what a stratification might look like for just two participants (the number of documents shown and percentage that are relevant may differ from the actual data):

A random subset of documents from each stratum was chosen and reviewed so that the percentage of the documents in the stratum that were relevant could be estimated. Multiplying that percentage by the number of documents in the stratum gives an estimate for the number of relevant documents in the stratum. Combining the results for the various strata allows precision and recall estimates to be computed for each participant. How could this be done for a team that didn’t participate? Before presenting some ideas, it will be useful to have some notation:
N[i] = number of documents in stratum i
n[i] = num docs in i that were assessed by TREC
n+[i] = num docs in i that TREC assessed as relevant
V[i] = num docs in i that vendor predicted were relevant
v[i] = num docs in i that vendor predicted were relevant and were assessed by TREC
v+[i] = num docs in i that vendor predicted were relevant and assessed as relevant by TREC

To make some of the discussion below more concrete, I’ll provide formulas for computing the number of true positives (TP), false positives (FP), and false negatives (FN). The recall and precision can then be computed from:
R = TP / (TP + FN)
P = TP / (TP + FP)
Here are some ideas I came up with:
1) They could have checked to see which strata the documents they predicted to be relevant fell into and applied the percentages TREC computed to their data. The problem is that since they probably didn’t identify all of the documents in a stratum as being relevant the percentage of documents that were estimated to be relevant for the stratum by TREC wouldn’t really be applicable. If their system worked really well, they may have only predicted that the truly relevant documents from the stratum were relevant. If their system worked badly, their system may have predicted that only the truly non-relevant documents from the stratum were relevant. This approach could give estimates that are systematically too low or too high. Here are the relevant formulas (summing over strata, i):
TP = Sum{ V[i] * n+[i] / n[i] }
FP = Sum{ V[i] * (1 – n+[i]/n[i]) }
FN = Sum{ (N[i] – V[i]) * n+[i] / n[i] }
2) Instead of using the percentages computed by TREC, they could have computed their own percentages by looking at only the documents in the stratum that they predicted were relevant and were reviewed by TREC to give a relevance determination. This would eliminate the possible bias from approach (1), but it also means that the percentages would be computed from a smaller sample, so the uncertainty in the percentage that are relevant would be bigger. The vendor didn’t provide confidence intervals for their results. Here is how the computation would go:
TP = Sum{ V[i] * v+[i] / v[i] }
FP = Sum{ V[i] * (1 – v+[i]/v[i]) }
FN = Sum{ (N[i] – V[i]) * (n+[i] – v+[i]) / (n[i] – v[i]) }
It’s possible that for some strata there would be no overlap between the documents TREC assessed and the documents the vendor predicted to be relevant since TREC typically assessed only about 4% of each stratum for Topic 207 (except the All-N stratum, where they assessed only 0.46%). This approach wouldn’t work for those strata since v[i] would be 0. For strata where v[i] is 0, one might use approach (1) and hope it isn’t too wrong.
3) A more sophisticated tweak on (2) would be to use the ratio n+[i]/n[i] from (1) to generate a Bayesian prior probability distribution for the proportion of documents predicted by the vendor to be relevant that actually are relevant, and then use v+[i] and v[i] to compute a posterior distribution for that proportion and use the mean of that distribution instead of v+[i]/v[i] in the computation. The idea is to have a smooth interpolation between using n+[i]/n[i] and using v+[i]/v[i] as the proportion of documents estimated to be relevant, where the interpolation would be closer to v+[i]/v[i] if v[i] is large (i.e., if there is enough data for v+[i]/v[i] to be reasonably accurate). The result would be sensitive to choices made in creating the Bayesian prior (i.e., how much variance to give the probability distribution), however.
4) They could have ignored all of the documents that weren’t reviewed in TREC (over 500,000 of them) and just performed their predictions and analysis on the 3,709 documents that had relevance assessments (training documents should come from the set TREC didn’t assess and should be reviewed by the vendor to simulate actual training at TREC being done by the participants). It would be very important to weight the results to compensate for the fact that those 3,709 documents didn’t all have the same probability of being selected for review. TREC oversampled the documents that were predicted to be relevant compared to the remainder (i.e., the number of documents sampled from a stratum was not simply proportional to the number of documents in the stratum), which allowed their stratification scheme to do a good job of comparing the participating teams to each other at the expense of having large uncertainty for some quantities like the total number of relevant documents. The prevalence of relevant documents in the full population was 1.5%, but 9.0% of the documents having relevance assessments were relevant. Without weighting the results to compensate for the uneven sampling, you would be throwing away over half a million non-relevant documents without giving the system being tested the opportunity to incorrectly predict that some of them are relevant, which would lead to an inflated precision estimate. The expression “shooting fish in a barrel” comes to mind. Weighting would be accomplished by dividing by the probability of the document having been chosen (after this article was published I learned that this is called the Horvitz-Thompson estimator, and it is what the TREC evaluation toolkit uses), which is just n[i]/N[i], so the computation would be:
TP = Sum{ (N[i]/n[i]) * v+[i] }
FP = Sum{ (N[i]/n[i]) * (v[i] – v+[i]) }
FN = Sum{ (N[i]/n[i]) * (n+[i] – v+[i]) }
Note that if N[i]/n[i] is equal to V[i]/v[i], which is expected to be approximately true since the subset of a stratum chosen for assessment by TREC is random, the result would be equal to that from (2). If N[i]/n[i] is not equal to V[i]/v[i] for a stratum, we would have the disturbing result that the estimate for TP+FP for that stratum would not equal the number of documents the vendor predicted to be relevant for that stratum, V[i].
5) The vendor could have ignored the TREC relevance determinations, simply doing their own. That would be highly biased in the vendor’s favor because there would be a level of consistency between relevance determinations for the training data and testing data that did not exist for TREC participants. At TREC the participants made their own relevance determinations to train their systems and a separate set of Topic Authorities made the final relevance judgments that determined the performance numbers. To the degree that participants came to different conclusions about relevance compared to the Topic Authorities, their performance numbers would suffer. A more subtle problem with this approach is that the vendor’s interpretation of the relevance criteria would inevitably be somewhat different from that of TREC assessors (studies have shown poor agreement between different review teams), which could make the classification task either easier or harder for a computer. As an extreme example, if the vendor took all documents containing the word “football” to be relevant and all other documents to be non-relevant, it would be very easy for a predictive coding system to identify that pattern and achieve good performance numbers.
Approaches (1)-(4) would all give the same results for the original TREC participants because for each stratum they would either have V[i]=0 (so v[i]=0 and v+[i]=0) or they would have V[i]=N[i] (so v[i]=n[i] and v+[i]=n+[i]). The approaches differ in how they account for the vendor predicting that only a subset of a stratum is relevant. None of the approaches described are great. Is there a better approach that I missed? TREC designed their strata to make the best possible comparisons between the participants. It’s hard to imagine how an analysis could be as accurate for a system that was not taken into account in the stratification process. If a vendor is tempted to make such comparisons, they should at least disclose their methodology and provide confidence intervals on their results so prospective clients can determine whether the performance numbers are actually meaningful.



 be giving a webinar on training of predictive coding systems and the new TAR 3.0 workflow (not to be confused with Ralph Losey’s Predictive Coding 3.0). This webinar should be accessible to those that are new to predictive coding while also providing new insights for those who are more experienced. Expect lots of graphs and animations. It will be held on December 10, 2015 at 1:00pm EST, and it will be recorded. Those who register will be able view the video during the three days following the webinar, so please register even if the live event doesn’t fit into your schedule.
be giving a webinar on training of predictive coding systems and the new TAR 3.0 workflow (not to be confused with Ralph Losey’s Predictive Coding 3.0). This webinar should be accessible to those that are new to predictive coding while also providing new insights for those who are more experienced. Expect lots of graphs and animations. It will be held on December 10, 2015 at 1:00pm EST, and it will be recorded. Those who register will be able view the video during the three days following the webinar, so please register even if the live event doesn’t fit into your schedule. The rationale for disclosing seed sets seems to be that the seed set is the input to the predictive coding system that determines which documents will be produced, so it is reasonable to ask for it to be disclosed so the requesting party can be assured that they will get what they wanted, similar to asking for a keyword search query to be disclosed.
The rationale for disclosing seed sets seems to be that the seed set is the input to the predictive coding system that determines which documents will be produced, so it is reasonable to ask for it to be disclosed so the requesting party can be assured that they will get what they wanted, similar to asking for a keyword search query to be disclosed.